Recently I faced an interesting challenge:
I had to continuously insert a large number of objects and immediately retrieve them in sorted (descending) order, every single time an insertion happened
loop {
insert -> sort -> return
}
My first thought was simple: just use a List<T>
- Insertions are O(1)
- Sorting is O(N logN)
But I started wondering… can we actually do better?
Table of Contents
- Trying PriorityQueue
- Benchmark Results (List vs PriorityQueue)
- Observations
- The FastMaxHeap Implementation
- Benchmark Results (Including Custom Heap)
Trying PriorityQueue
- Insertions are O(logN)
- The queue stays sorted automatically
In theory, this should win..
But .NET has its own ecosystem, its own optimizations, and its own quirks. You never really know until you benchmark
So I did exactly that.
Benchmark Results (List vs PriorityQueue)
| Method | N | Mean | Error | StdDev | Gen0 | Gen1 | Gen2 | Allocated |
|--------------------- |-------- |-----------------:|---------------:|---------------:|---------:|---------:|---------:|-----------:|
| ListSort | 10 | 49.54 ns | 0.642 ns | 0.536 ns | 0.0006 | - | - | 96 B |
| PriorityQueueMaxHeap | 10 | 82.35 ns | 1.666 ns | 3.622 ns | 0.0021 | - | - | 344 B |
| ListSort | 100 | 463.78 ns | 9.013 ns | 12.635 ns | 0.0024 | - | - | 456 B |
| PriorityQueueMaxHeap | 100 | 631.30 ns | 12.504 ns | 23.485 ns | 0.0134 | - | - | 2208 B |
| ListSort | 1000 | 8,502.69 ns | 166.158 ns | 155.424 ns | 0.0153 | - | - | 4056 B |
| PriorityQueueMaxHeap | 1000 | 4,972.78 ns | 98.582 ns | 266.522 ns | 0.0992 | - | - | 16616 B |
| ListSort | 10000 | 298,924.86 ns | 4,962.533 ns | 4,641.956 ns | - | - | - | 40056 B |
| PriorityQueueMaxHeap | 10000 | 145,681.72 ns | 2,868.882 ns | 4,114.465 ns | 4.3945 | 3.9063 | 3.9063 | 262491 B |
| ListSort | 100000 | 4,296,777.64 ns | 52,767.400 ns | 49,358.659 ns | 7.8125 | 7.8125 | 7.8125 | 400061 B |
| PriorityQueueMaxHeap | 100000 | 1,924,881.06 ns | 37,111.871 ns | 34,714.467 ns | 46.8750 | 46.8750 | 46.8750 | 2097674 B |
| ListSort | 1000000 | 49,893,336.22 ns | 322,795.615 ns | 286,149.905 ns | - | - | - | 4000056 B |
| PriorityQueueMaxHeap | 1000000 | 15,571,538.49 ns | 290,155.221 ns | 284,971.224 ns | 156.2500 | 156.2500 | 156.2500 | 16777787 B |
Observations
We can observe the following:
- For very small N (< 1000), List.Sort() is still faster
PriorityQueueallocates x2-x4 more memory than list does- At medium/large scales,
PriorityQueueis faster, but with a huge allocation
And this is because the dotnet team behind Microsoft has done an incredible job at optimizing lists as much as possible.
Whereas for a PriorityQueue you have more fields per entry, you've got comparer logic, resizing, metadata and structures that allocate on the heap
So I thought to myself, I know that PriorityQueue is conceptually the right structure,
so what if I just implement my own max-heap manually and essentially ditch all that unnecessary work,
for my case at least, that PriorityQueue class does behind the scenes, and use a simple array with the
classic heapify logic
If you're not familiar with how heapify works here's a trivial diagram:
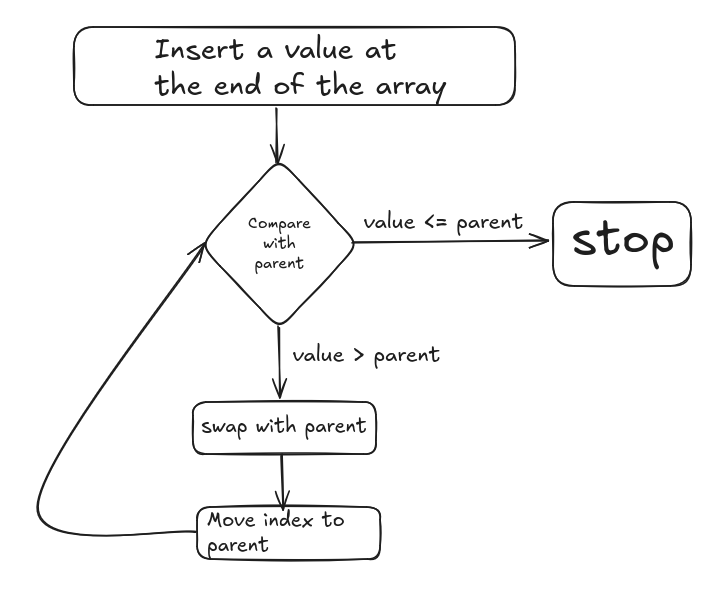
Our custom heap is just:
- a flat
int[] - an index counter
- bubble-up logic
There is no priority tuple, no comparer, no metadata, nothing.
It's just a pure max-heap using the classic parent/child index formula:
parent = (i - 1) / 2
left = 2*i + 1
right = 2*i + 2
The FastMaxHeap Implementation
The code would look like this:
public class FastMaxHeap
{
private int[] _data;
private int _count;
public FastMaxHeap(int capacity)
{
_data = new int[capacity];
_count = 0;
}
public int Max => _data[0];
public void Add(int value)
{
int i = _count++;
_data[i] = value;
while (i > 0)
{
int parent = (i - 1) >> 1;
if (_data[parent] >= _data[i])
{
break;
}
(_data[parent], _data[i]) = (_data[i], _data[parent]);
i = parent;
}
}
}
Benchmark Results (Including Custom Heap)
And the results were even more interesting:
| Method | N | Mean | Error | StdDev | Gen0 | Gen1 | Gen2 | Allocated |
|--------------------- |-------- |-----------------:|---------------:|---------------:|---------:|---------:|---------:|-----------:|
| ListSort | 10 | 49.54 ns | 0.642 ns | 0.536 ns | 0.0006 | - | - | 96 B |
| PriorityQueueMaxHeap | 10 | 82.35 ns | 1.666 ns | 3.622 ns | 0.0021 | - | - | 344 B |
| FastMaxHeapInsert | 10 | 35.92 ns | 0.729 ns | 1.352 ns | 0.0005 | - | - | 96 B |
| ListSort | 100 | 463.78 ns | 9.013 ns | 12.635 ns | 0.0024 | - | - | 456 B |
| PriorityQueueMaxHeap | 100 | 631.30 ns | 12.504 ns | 23.485 ns | 0.0134 | - | - | 2208 B |
| FastMaxHeapInsert | 100 | 317.84 ns | 6.196 ns | 6.887 ns | 0.0024 | - | - | 456 B |
| ListSort | 1000 | 8,502.69 ns | 166.158 ns | 155.424 ns | 0.0153 | - | - | 4056 B |
| PriorityQueueMaxHeap | 1000 | 4,972.78 ns | 98.582 ns | 266.522 ns | 0.0992 | - | - | 16616 B |
| FastMaxHeapInsert | 1000 | 3,102.24 ns | 58.571 ns | 54.787 ns | 0.0229 | - | - | 4056 B |
| ListSort | 10000 | 298,924.86 ns | 4,962.533 ns | 4,641.956 ns | - | - | - | 40056 B |
| PriorityQueueMaxHeap | 10000 | 145,681.72 ns | 2,868.882 ns | 4,114.465 ns | 4.3945 | 3.9063 | 3.9063 | 262491 B |
| FastMaxHeapInsert | 10000 | 32,425.53 ns | 644.140 ns | 1,330.261 ns | 0.2441 | - | - | 40056 B |
| ListSort | 100000 | 4,296,777.64 ns | 52,767.400 ns | 49,358.659 ns | 7.8125 | 7.8125 | 7.8125 | 400061 B |
| PriorityQueueMaxHeap | 100000 | 1,924,881.06 ns | 37,111.871 ns | 34,714.467 ns | 46.8750 | 46.8750 | 46.8750 | 2097674 B |
| FastMaxHeapInsert | 100000 | 1,096,367.59 ns | 11,521.541 ns | 10,777.257 ns | 9.7656 | 9.7656 | 9.7656 | 400125 B |
| ListSort | 1000000 | 49,893,336.22 ns | 322,795.615 ns | 286,149.905 ns | - | - | - | 4000056 B |
| PriorityQueueMaxHeap | 1000000 | 15,571,538.49 ns | 290,155.221 ns | 284,971.224 ns | 156.2500 | 156.2500 | 156.2500 | 16777787 B |
| FastMaxHeapInsert | 1000000 | 10,713,933.71 ns | 148,080.628 ns | 131,269.619 ns | 46.8750 | 46.8750 | 46.8750 | 4000086 B |
The key take-aways from this article are two:
- Always benchmark. Even if you're 99% sure, it's always best if you've got numbers in front of you to prove your point
- Even if something looks faster on paper, different languages and runtimes have very different implementation details
So, if you want raw performance + minimal allocations you may as well do it yourself It's a perfect choice for real-time systems, games etc